
Quota sampling is one of the most widely used non-probability sampling methods in research, offering researchers a practical and cost-effective way to gather data when random sampling proves challenging or impossible. This sampling technique involves selecting participants based on predetermined characteristics or “quotas” that reflect specific population segments, allowing researchers to maintain control over the composition of their sample while working within practical constraints.
Unlike probability sampling methods where every member of a population has a known chance of selection, quota sampling relies on researcher judgment to fill predetermined categories until specific numbers are reached. This approach has found particular favor in market research, political polling, and social science studies where researchers need to ensure representation across key demographic groups without the expense and complexity of true random sampling.
Understanding quota sampling becomes essential for anyone conducting research in today’s fast-paced environment, where time constraints, budget limitations, and accessibility issues often make probability sampling impractical.
The Core Concept
Quota sampling operates on a straightforward yet powerful principle: researchers divide their target population into distinct subgroups based on relevant characteristics, then systematically collect data from each subgroup until predetermined quotas are filled. This method bridges the gap between completely random sampling and convenience sampling, offering structure and representation while maintaining practical feasibility.
Population Stratification and Characteristics
The core concept revolves around stratification, where the population is segmented according to characteristics deemed important for the research objectives. These characteristics might include demographic variables such as age, gender, income level, education, geographic location, or behavioral factors like purchasing habits, political affiliation, or product usage patterns. The key distinction lies in how participants are selected within each stratum: rather than using random selection, researchers employ their judgment to identify and recruit suitable participants until each quota is met.
Non-Probability Nature and Selection Bias
This non-probability nature means that while quota sampling can provide good representation across specified characteristics, it cannot guarantee that every member of the population has an equal chance of selection. The researcher’s discretion in choosing participants within each quota category introduces an element of selection bias that distinguishes quota sampling from its probability-based counterparts.
Benefits of Controlled Sample Composition
The stratification element in quota sampling serves multiple purposes beyond simple representation. It ensures that minority groups or smaller population segments are adequately represented in the final sample, prevents any single demographic group from dominating the results, and allows researchers to make comparisons between different subgroups with confidence. This controlled approach to sample composition makes quota sampling particularly valuable when studying diverse populations or when specific subgroup analysis is crucial to the research objectives.
How Quota Sampling Works
Pre-Implementation Planning and Population Analysis
The implementation of quota sampling follows a systematic process that begins long before data collection starts. Researchers must first conduct thorough population analysis to identify the most relevant characteristics for their study. This involves examining existing demographic data, considering the research objectives, and determining which population segments are most critical to include for meaningful results.
Step-by-Step Implementation Process
Identifying Relevant Population Characteristics
The step-by-step process begins with identifying relevant population characteristics. Researchers analyze their target population to determine which demographic, behavioral, or attitudinal variables are most important for their study. For a consumer behavior study, relevant characteristics might include age groups, income brackets, geographic regions, and purchasing frequency. For political research, variables could encompass party affiliation, voting history, education level, and residential area type.
Determining Quota Proportions
Once characteristics are identified, researchers must determine appropriate quota proportions. This crucial step can follow two approaches: proportional representation based on actual population distributions, or strategic allocation based on research needs. Proportional quotas mirror the population’s composition, ensuring that if 30% of the target population falls within a specific age group, 30% of the sample will also represent that group. Strategic allocation, however, might overrepresent certain groups to enable meaningful subgroup analysis or to ensure adequate representation of minority populations.
Participant Recruitment and Selection
The recruitment phase involves actively seeking participants who fit the remaining quota requirements. Unlike random sampling where participants are selected through systematic processes, quota sampling requires researchers to identify and approach potential participants who match the needed characteristics. This might involve recruiting through multiple channels: online panels, telephone directories, social media platforms, public locations, or professional networks.
Monitoring and Quality Control
Throughout the collection process, researchers continuously monitor quota fulfillment, adjusting their recruitment strategies as certain quotas fill more quickly than others. The process concludes when all predetermined quotas are met, regardless of whether additional willing participants are available. This quota-driven stopping point ensures that the final sample maintains the desired composition across all specified characteristics.
The Role of Researcher Discretion
Researcher discretion plays a significant role throughout this process. Within each quota category, researchers choose which specific individuals to include based on availability, willingness to participate, and practical considerations. This discretion, while providing flexibility and efficiency, also introduces the potential for selection bias that researchers must acknowledge and address in their analysis and reporting.
Types of Quota Sampling
Proportional vs. Non-Proportional Quota Sampling
Proportional Quota Sampling
Proportional quota sampling represents the most straightforward approach, where quota sizes directly reflect the actual distribution of characteristics within the target population. If census data indicates that 25% of a city’s population falls within the 18-30 age bracket, a proportional quota sample would ensure that exactly 25% of participants represent this age group. This approach maximizes the sample’s representativeness of the broader population and facilitates generalization of findings, though it may result in very small subgroups that limit detailed analysis of minority populations.
Non-Proportional Quota Sampling
Non-proportional quota sampling deliberately deviates from population proportions to serve specific research purposes. Researchers might choose to oversample certain groups to enable meaningful statistical analysis of smaller population segments or to ensure adequate representation of groups that might otherwise be underrepresented. For instance, a study examining healthcare experiences across ethnic groups might allocate equal quotas to each ethnic category, even though some groups represent much smaller proportions of the general population. This approach enhances the researcher’s ability to make comparisons between groups and identify patterns that might be obscured in proportional sampling.
Controlled vs. Uncontrolled Quotas
Controlled Quotas
The distinction between controlled and uncontrolled quotas reflects the complexity of quota management during data collection. Controlled quotas involve simultaneous management of multiple characteristics, creating intersecting categories that must be filled systematically. A controlled quota might require specific numbers of participants who are simultaneously female, aged 25-35, college-educated, and residing in urban areas. This approach ensures representation across multiple dimensions but significantly complicates the recruitment process and may extend data collection timelines.
Uncontrolled Quotas
Uncontrolled quotas, in contrast, manage each characteristic independently without regard to intersections between variables. Researchers might establish separate quotas for gender, age, and education without requiring specific combinations of these characteristics. While simpler to implement and faster to complete, uncontrolled quotas may result in uneven distribution across characteristic combinations, potentially leaving some intersectional groups underrepresented.
Advanced Quota Strategies
Sequential Quota Filling
Sequential quota filling represents another important variation where researchers prioritize certain characteristics over others. Primary quotas might focus on the most critical variables for the research objectives, while secondary quotas address additional characteristics as opportunities arise. This hierarchical approach proves particularly useful when working with limited time or resources, allowing researchers to ensure adequate representation on the most important dimensions while remaining flexible on secondary considerations.
Mixed Quota Approaches
Mixed quota approaches combine elements from different quota types within a single study. Researchers might use proportional quotas for some characteristics while applying non-proportional allocation to others, or they might employ controlled quotas for primary variables while using uncontrolled methods for secondary characteristics. These hybrid approaches offer flexibility and can be tailored to address specific research challenges while maintaining overall sample integrity.
Quota Sampling vs. Other Methods
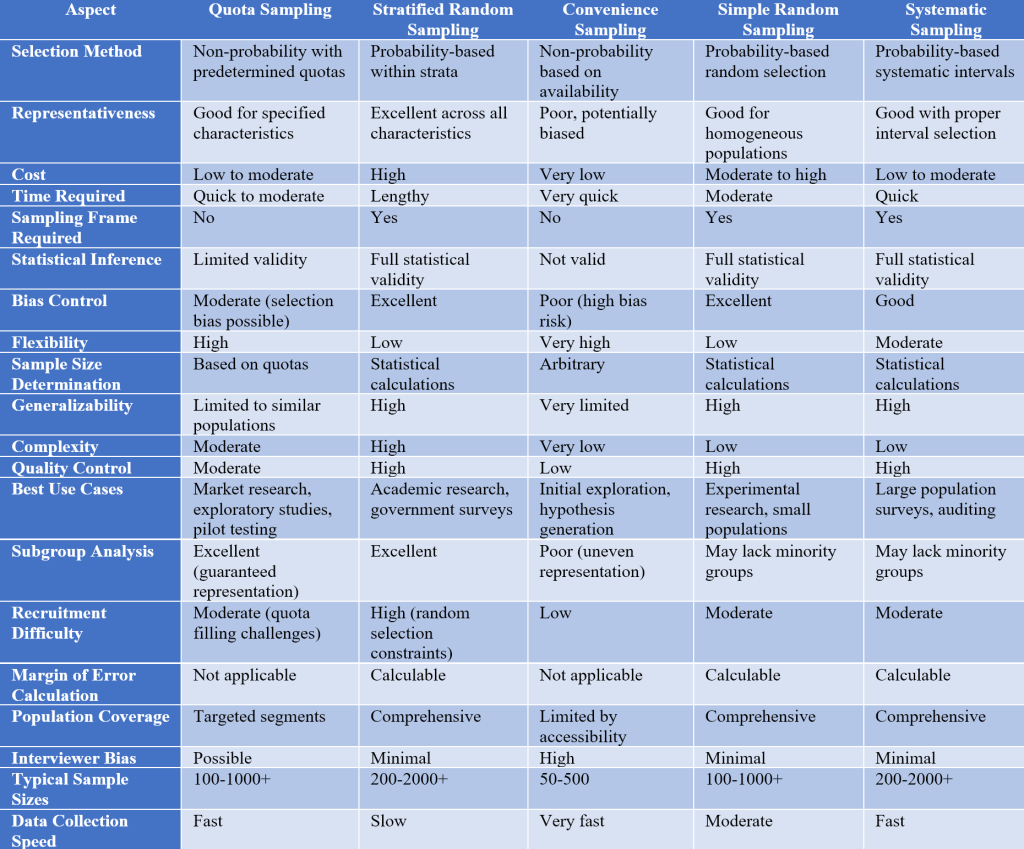
Detailed Examples Across Different Fields
Market Research Example: Consumer Smartphone Preferences
Research Scenario and Objectives
TechInsight Research conducted a comprehensive study to understand consumer preferences for smartphone features across different demographic segments. The company needed to launch a new device within six months and required actionable insights about feature priorities, price sensitivity, and brand perceptions across diverse consumer groups. Traditional random sampling would have been too costly and time-consuming given the tight timeline and budget constraints.
Population Characteristics and Quota Structure
The research team identified four critical demographic characteristics based on existing market data and strategic objectives. Age groups were segmented into 18-30 (tech-savvy early adopters), 31-45 (established professionals), and 46-60 (mature consumers with specific needs). Gender representation ensured equal male and female perspectives, while income levels were divided into under $40,000, $40,000-$80,000, and over $80,000 annually to capture different price sensitivity segments.
The final quota structure allocated 400 total participants across these characteristics. The 18-30 age group received 40% allocation (160 participants) due to their influence on technology trends, while 31-45 and 46-60 groups each received 30% (120 participants each). Gender quotas maintained 50-50 distribution within each age group, and income distribution followed 30% low, 45% middle, and 25% high-income brackets based on target market analysis rather than population proportions.
Implementation Process and Data Collection Methods
The research team employed multiple recruitment channels to efficiently fill quotas. Online panels provided the primary recruitment source, allowing for quick demographic screening and quota monitoring. Shopping mall intercepts targeted specific age groups during different times of day, with morning hours focusing on older demographics and evening hours capturing younger consumers. Social media advertising enabled targeted recruitment based on age and income indicators, while telephone surveys reached participants who might be underrepresented in digital channels.
Quota monitoring occurred in real-time through a centralized tracking system. As certain demographic combinations filled quickly (particularly young, high-income males), recruiters shifted focus to harder-to-reach segments. The team discovered that middle-aged, lower-income women required additional effort, leading to partnerships with community organizations and extended recruitment in suburban locations.
Results and Strategic Implications
The quota sampling approach successfully captured diverse perspectives that informed product development decisions. Younger participants prioritized camera quality and processing speed, middle-aged consumers emphasized battery life and ease of use, while older participants valued customer support and device durability. Income-based differences revealed distinct price sensitivity patterns, with lower-income segments preferring fewer premium features at reduced costs.
Political Polling Example: Pre-Election Voting Intentions
Research Context and Timeline Pressures
PoliticalPulse Surveys conducted weekly tracking polls during the final two months before a gubernatorial election. The organization needed to provide reliable voting intention data while managing costs and maintaining rapid turnaround times for media clients. Random digit dialing would have been prohibitively expensive for weekly polling, while convenience sampling risked significant bias in political preferences.
Quota Variables and Strategic Considerations
The polling team established quotas based on previous election turnout patterns and current voter registration data. Geographic regions were divided into urban cores (35% of sample), suburban areas (40%), and rural districts (25%), reflecting likely voter distribution rather than general population proportions. Party affiliation quotas allocated 40% Democrats, 35% Republicans, and 25% Independents based on recent registration trends.
Additional quotas addressed education levels (30% high school or less, 45% some college, 25% college graduates), age groups weighted toward older demographics likely to vote, and gender balance within each category. Race and ethnicity quotas ensured representation of minority communities whose turnout could influence election outcomes.
Methodological Challenges and Solutions
The research team faced unique challenges in political polling, including respondent reluctance to participate and potential bias in self-reported party affiliation. Multiple contact methods combined landline and mobile phone sampling with online panel recruitment to capture different demographic groups effectively. Quota monitoring required daily adjustments as certain political groups showed higher or lower response rates.
The team implemented sophisticated weighting procedures to address quota imbalances that emerged during data collection. When rural Republican quotas proved difficult to fill through traditional methods, researchers partnered with local community organizations and adjusted calling schedules to reach working-class voters during evening hours.
Accuracy and Validation Measures
Post-election analysis validated the quota sampling approach’s effectiveness. Final polling results accurately predicted the election outcome within the margin of error, with particular success in capturing suburban swing voter behavior. The quota structure successfully identified key demographic shifts that influenced the election, including higher than expected turnout among college-educated women and lower participation among young voters.
Healthcare Research Example: Patient Satisfaction Across Hospital Services
Healthcare Setting and Research Objectives
Regional Medical Center sought to understand patient satisfaction patterns across different service areas to guide quality improvement initiatives and resource allocation decisions. The hospital served diverse communities with varying socioeconomic backgrounds, insurance coverage, and health conditions, making representative sampling crucial for actionable insights.
Medical and Demographic Quota Considerations
The research design incorporated both medical and demographic quotas to ensure comprehensive coverage. Medical service quotas allocated participants across emergency department (25%), inpatient services (35%), outpatient clinics (25%), and surgical services (15%) based on patient volume and strategic importance. Length of stay categories divided participants into same-day visits, 1-3 day stays, and extended stays over three days.
Demographic quotas addressed age groups with particular attention to elderly patients (65+) who comprised 40% of the sample despite representing 25% of the general population, reflecting their higher healthcare utilization rates. Insurance type quotas included private insurance (45%), Medicare (30%), Medicaid (20%), and uninsured patients (5%) to capture different payment experiences and access patterns.
Ethical Considerations and Recruitment Protocols
Healthcare research required additional ethical safeguards and privacy protections. The research team obtained IRB approval and implemented HIPAA-compliant procedures for patient contact and data collection. Recruitment occurred through multiple channels including post-discharge phone calls, mailed invitations, and in-person requests during non-critical care moments.
Special attention addressed vulnerable populations, including elderly patients with cognitive limitations and non-English speaking communities. Translated surveys and culturally competent interviewers ensured meaningful participation across diverse patient populations. The quota structure specifically included provisions for patients with different health literacy levels and communication preferences.
Quality Improvement Applications
The quota sampling results revealed significant satisfaction variations across patient characteristics that pure convenience sampling might have missed. Elderly patients reported different priorities than younger patients, emphasizing communication clarity and care coordination over amenities and efficiency. Insurance type strongly predicted satisfaction with billing processes and discharge planning, leading to targeted improvements in financial counseling services.
Academic Research Example: University Student Stress and Mental Health
Campus Research Environment
State University’s Counseling and Psychological Services department partnered with the Education Research Institute to examine stress levels and mental health resource utilization across different student populations. The study aimed to inform campus mental health policy and resource allocation while ensuring representation across diverse academic and demographic groups.
Academic and Social Quota Framework
The quota structure reflected the university’s academic diversity and student body composition. Academic year quotas allocated 25% freshmen, 25% sophomores, 25% juniors, and 25% seniors to capture developmental differences in stress experiences and coping strategies. Major field categories included STEM (40%), Liberal Arts (25%), Business (20%), and Other disciplines (15%) based on enrollment proportions and preliminary data suggesting field-specific stress patterns.
Additional quotas addressed full-time versus part-time status (85% and 15% respectively), residential arrangements (on-campus, off-campus, commuter students), and international versus domestic student status. First-generation college student representation received special attention with a 30% quota allocation despite comprising only 20% of the student body, recognizing their unique stressors and support needs.
Campus-Based Recruitment Strategies
Recruitment leveraged multiple campus touchpoints to reach diverse student populations effectively. Classroom announcements targeted specific majors and academic levels, while residence hall programming reached traditional-age students living on campus. Commuter student recruitment required different approaches, including partnerships with parking services, part-time student organizations, and online course platforms.
The research team discovered that certain quota combinations proved challenging to fill, particularly part-time senior STEM students and international students in specific majors. Extended recruitment periods and targeted outreach through international student services and professional student organizations addressed these gaps.
Policy and Program Development Outcomes
The quota sampling approach successfully identified distinct stress patterns and resource needs across student populations. First-generation students reported higher academic stress but lower help-seeking behavior, leading to targeted outreach and support programming. International students faced unique stressors related to cultural adjustment and visa concerns, informing specialized counseling services. STEM students showed different stress patterns than liberal arts students, leading to discipline-specific mental health programming and faculty training initiatives.
FAQs
How is quota sampling different from random sampling?
In quota sampling, participants are selected based on specific characteristics, but not randomly. In random sampling, every individual in the population has an equal chance of being chosen.
Is quota sampling reliable for academic research?
Quota sampling can provide useful insights, especially when subgroup representation is important. However, due to its non-random nature, it may not be ideal for studies requiring statistical generalization.
Can quota sampling be combined with other methods?
Yes, researchers sometimes combine quota sampling with convenience or purposive sampling to reach participants who fit the quotas more efficiently.